פורמט FASTQ
פורמט FASTQ הוא פורמט בביואינפורמטיקה מבוסס טקסט אשר אוצר בתוכו לא רק את הרצף הביולוגי (כפי שעושה פורמט FASTA), אלא גם את ציון האיכות שלו כפי שנקלט במכשיר הריצוף. הן הרצף הביולוגי והן ציון האיכות מסומנים בקיצור על ידי תווים מסוימים. לרוב, מדובר ברצף נוקליאוטידים המיוצגים על ידי האותיות A,C,T,G אשר מייצגות את ארבעת הבסיסים המרכיבים את ה-DNA. ציון האיכות מסומן על ידי קוד ASCII.
פורמט זה פותח במכון סנגר של קרן ולקם במטרה לקשור את רצפי ה-FASTA למידע על איכותו. עם השנים פורמט זה הפך דה פקטו לתקן בו אוצרים פלט של ריצוף בתפוקה גבוהה (high-throughput sequencing).
מבנה הפורמט
קובץ FASTQ מכיל בתורו ארבע שורות:
- שורה 1: מתחילה עם הסימן @, ולאחריו תיאור של הרצף, בדומה לסימן < בפורמט FASTA. תיאור זה אינו הכרחי, ומיועד לזיהוי הרצף.
- שורה 2: מכילה את האותיות המסמלות את הרצף הביולוגי.
- שורה 3: מתחילה עם הסימן + ויכולה להכיל הערות כמו אלו המופיעות בשורה 1. תיאור זה אינו הכרחי, ומיועד לזיהוי הרצף.
- שורה 4: מכילה את קוד הASCII המבטא את ציון האיכות של האות הממוקמת באותו מקום בשורה 2. אורך שורה זו בהכרח שווה לאורכה של שורה 2.
קובץ FASTQ המכיל קובץ בודד יראה כדוגמה זו:
@SEQ_ID GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT + !''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65
סימן הקריאה בראשית השורה הרביעית משמאל מייצגת את האיכות של הנוקליאוטיד G בשורה השנייה משמאל. זהו ציון האיכות הנמוך ביותר, כאשר ציון ~ הוא הגבוה ביותר. ציוני האיכות הנתונים מקבילים לתווים 33–126 ב-טבלת ASCII. בתחילה הפורמט אפשר לשבור שורות כאשר הרצף היה ארוך, אך מכיוון שהתווים @ ו-+ יכולים לשמש גם בקוד ASCII, דבר זה לא מקובל כיום.
מזהים רצפיים בשיטת אילומינה
רצפים אשר רוצפו במכונות של חברת אילומינה מקבלים זיהוי מערכתי.
@HWUSI-EAS100R:6:73:941:1973#0/1
| HWUSI-EAS100R | שם המכשיר בו נעשה הריצוף. ייחודי לכל מכשיר. |
| 6 | מספר תא ההרצה (flowcell). |
| 73 | מספר האזור בתוך תא ההרצה. |
| 941 | קואורדינטת ציר X של האשכול בתוך האזור. |
| 1973 | קואורדינטת ציר Y של האשכול בתוך האזור. |
| #0 | אינדקס לדוגמה (במידה ועורבבו כמה דוגמאות שונות יחד) |
| /1 | המספר בזוג, האם נעשית קריאה מכיוון אחד או משני הכיוונים (קריאה בזוג). |
בגרסאות מאוחרות של אילומינה (החל מגרסה 1.4) החלו להשתמש ב-#NNNNNN במקום ב-#0 כדי לסמן ערבוב של דוגמאות. כלומר, מקריאת הפלט נוכל ללמוד לא רק על כמות הדוגמאות שעורבבו, אלא גם מידע רצפי, כאשר כל N מסמל את אחד מארבעת הנוקליאוטידים ובכך יוצר ברקוד ייחודי לדוגמה.
עם הזמן ופיתוח תוכנות שונות לאנליזה של המידע הרצפי, חלק ממאפייני הזיהוי הרצפי התעדכנו, וכן נוספו חדשים אשר אינם מיוצגים בדוגמה הנ"ל.
וריאציות
איכות
מדד איכות Q מסמל את ההסתברות (p) שבסיס מסוים אינו מה שהמכונה זיהתה. ישנם שתי משוואות הנמצאות בשימוש. הראשונה מודדת את האמינות של בסיס, וידועה כציון איכות פרד (Phred quality score):

השנייה מודדת את הסיכוי לטעות (p/(1-p במקום את ההסתברות (p):

בשתי השיטות הללו הציון המתקבל דומה בציונים הגבוהים, אך ישנו פער בציונים הנמוכים (בסביבות Q < 13, שזה מקביל בערך ל-p > 0.05).
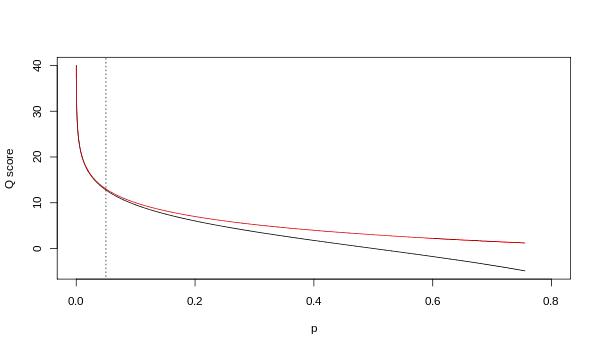
לאורך תקופה מסוימת, לא היה ברור באיזה אחד מהמשוואות הנ"ל משתמשת אילומינה לצורך האנליזה. בגרסה 1.5 של תוכנית הניתוח (pipeline) הם הצהירו שהם משתמשים בציון איכות פרד.
קידוד
- בפורמט סנגר ניתן לקודד ציון איכות פרד שנע בין 0–93 באמצעות סמלי ASCII 33-126.
סיומת קובץ
אין תקן מסוים לסיומת קובץ לפורמט זה. עם זאת, הסיומות fq. ו-fastq. נמצאים בשימוש.
ראו גם

רישיון cc-by-sa 3.0